



































The synthetic intelligence (AI) panorama continues to evolve, demanding fashions able to dealing with huge datasets and delivering exact insights. Fulfilling these wants, researchers at NVIDIA and MIT have lately launched a Visible Language Mannequin (VLM), VILA. This new AI mannequin stands out for its distinctive means to purpose amongst a number of pictures. Furthermore, it facilitates in-context studying and comprehends movies, marking a big development in multimodal AI methods.
Additionally Learn: Insights from NVIDIA’s GTC Convention 2024
The Evolution of AI Fashions
Within the dynamic discipline of AI analysis, the pursuit of steady studying and adaptation stays paramount. The problem of catastrophic forgetting, whereby fashions battle to retain prior information whereas studying new duties, has spurred revolutionary options. Strategies like Elastic Weight Consolidation (EWC) and Expertise Replay have been pivotal in mitigating this problem. Moreover, modular neural community architectures and meta-learning approaches supply distinctive avenues for enhancing adaptability and effectivity.
Additionally Learn: Reka Reveals Core – A Slicing-Edge Multimodal Language Mannequin
The Emergence of VILA
Researchers at NVIDIA and MIT have unveiled VILA, a novel visible language mannequin designed to handle the restrictions of present AI fashions. VILA’s distinctive method emphasizes efficient embedding alignment and dynamic neural community architectures. Leveraging a mixture of interleaved corpora and joint supervised fine-tuning, VILA enhances each visible and textual studying capabilities. This manner, it ensures sturdy efficiency throughout numerous duties.
Enhancing Visible and Textual Alignment
To optimize visible and textual alignment, the researchers employed a complete pre-training framework, using large-scale datasets corresponding to Coyo-700m. The builders have examined varied pre-training methods and included strategies like Visible Instruction Tuning into the mannequin. Because of this, VILA demonstrates exceptional accuracy enhancements in visible question-answering duties.
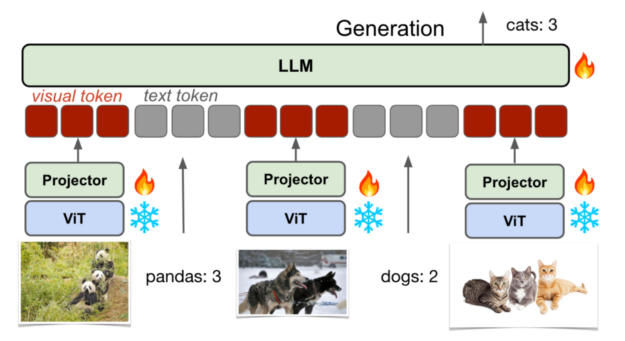
Efficiency and Adaptability
VILA’s efficiency metrics converse volumes, showcasing vital accuracy positive aspects in benchmarks like OKVQA and TextVQA. Notably, VILA reveals distinctive information retention, retaining as much as 90% of beforehand discovered info whereas adapting to new duties. This discount in catastrophic forgetting underscores VILA’s adaptability and effectivity in dealing with evolving AI challenges.
Additionally Learn: Grok-1.5V: Setting New Requirements in AI with Multimodal Integration
Our Say
VILA’s introduction marks a big development in multimodal AI, providing a promising framework for visible language mannequin improvement. Its revolutionary method to pre-training and alignment highlights the significance of holistic mannequin design in reaching superior efficiency throughout numerous functions. As AI continues to permeate varied sectors, VILA’s capabilities promise to drive transformative improvements. It’s certainly paving the way in which for extra environment friendly and adaptable AI methods.
Observe us on Google Information to remain up to date with the newest improvements on the planet of AI, Information Science, & GenAI.






{kind=link}