
































A lot of the curiosity surrounding synthetic intelligence (AI) is caught up with the battle of competing AI fashions on benchmark assessments or new so-called multi-modal capabilities.
OpenAI proclaims a video functionality, Sora, that stuns the world, Google responds with Gemini’s capability to select a body of video, and the open-source software program neighborhood shortly unveils novel approaches that pace previous the dominant industrial applications with better effectivity.
However customers of Gen AI’s massive language fashions, particularly enterprises, could care extra a few balanced strategy that produces legitimate solutions speedily.
A rising physique of labor suggests the expertise of retrieval-augmented technology, or RAG, might be pivotal in shaping the battle between massive language fashions (LLMs).
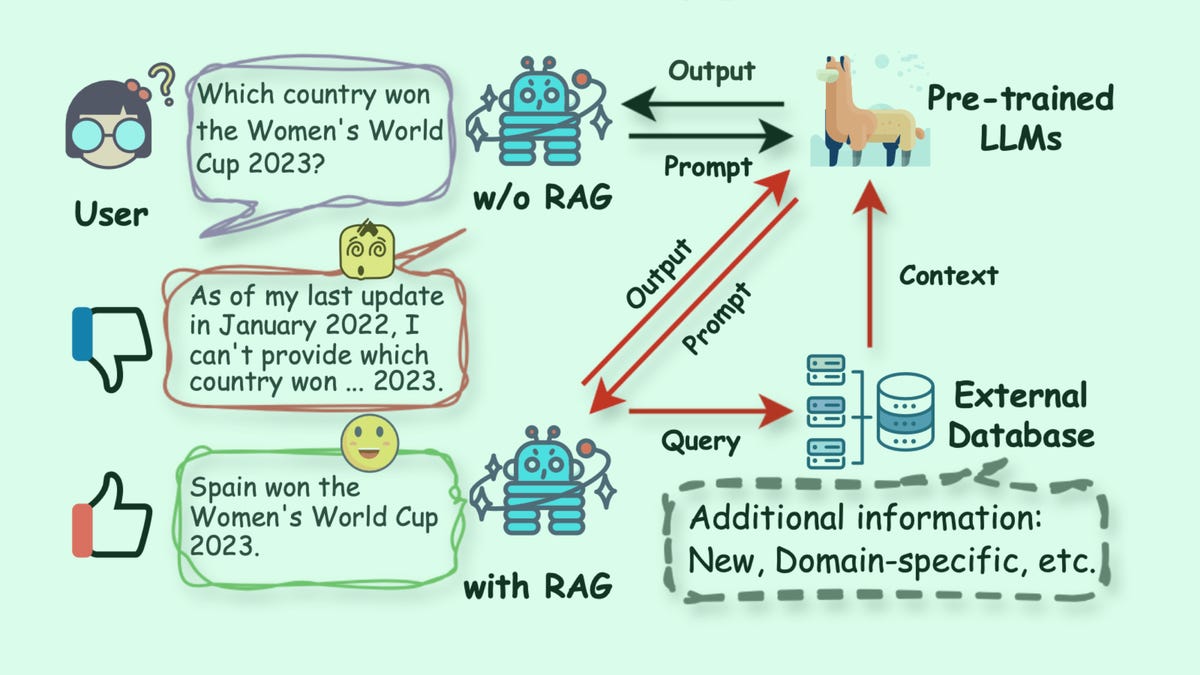
RAG is the observe of getting an LLM reply to a immediate by sending a request to some exterior knowledge supply, similar to a “vector database”, and retrieve authoritative knowledge. The commonest use of RAG is to scale back the propensity of LLMs to supply “hallucinations”, the place a mannequin asserts falsehoods confidently.
Business software program distributors, similar to search software program maker Elastic, and “vector” database vendor Pinecone, are speeding to promote applications that permit firms hook as much as databases and retrieve authoritative solutions grounded in, for instance, an organization’s product knowledge.
What’s retrieved can take many varieties, together with paperwork from a doc database, photos from an image file or video, or items of code from a software program growth code repository.
What’s already clear is the retrieval paradigm will unfold far and huge to all LLMs, each for industrial and client use circumstances. Each generative AI program may have hooks into exterior sources of knowledge.
At the moment, that course of may be achieved with operate calling, which OpenAI and Anthropic supply for his or her GPT and Claude applications respectively. These easy mechanisms present restricted entry to knowledge for restricted queries, similar to getting the present climate in a metropolis.
Operate calling will most likely should meld with, or be supplanted, by RAG sooner or later to increase what LLMs can supply in response.
That shift implies RAG will turn into commonplace in how most AI fashions carry out.
And that prominence raises points. On this admittedly early section of RAG’s growth, totally different LLMs carry out in another way when utilizing RAG, doing a greater or worse job of dealing with the knowledge that the RAG software program sends again to the LLM from the database. That distinction signifies that RAG turns into a brand new issue within the accuracy and utility of LLMs.
RAG, at the same time as early because the preliminary coaching section of AI fashions, might begin to have an effect on the design issues for LLMs. Till now, AI fashions have been developed in a vacuum, constructed as pristine scientific experiments which have little connection to the remainder of knowledge science.
There could also be a a lot nearer relationship sooner or later between the constructing and coaching of neural nets for generative AI and the downstream instruments of RAG that may play a task in efficiency and accuracy.
Pitfalls of LLMs with retrieval
Merely making use of RAG has been proven to extend the accuracy of LLMs, however it could additionally produce new issues.
For instance, what comes out of a database can lead LLMs into conflicts which are then resolved by additional hallucinations.
In a report in March, researchers on the College of Maryland discovered that GPT-3.5 can fail even after retrieving knowledge through RAG.
“The RAG system should battle to supply correct info to customers in circumstances the place the context offered falls past the scope of the mannequin’s coaching knowledge,” they write. The LLM would at instances “generate credible hallucinations by interpolating between factual content material.”
Scientists are discovering that design selections of LLMs can have an effect on how they carry out with retrieval, together with the standard of the solutions gotten again.
A examine this month by students at Peking College famous that “the introduction of retrieval unavoidably will increase the system complexity and the variety of hyper-parameters to tune,” the place hyper-parameters are selections made about how one can practice the LLM.
For instance, when a mannequin chooses from a number of doable “tokens”, together with which tokens to choose from the RAG knowledge, one can dial up or down how broadly it searches, that means how nice or slim a pool of tokens to select from.
Selecting a small group, referred to as “top-k sampling”, was discovered by the Peking students to “enhance attribution however hurt fluency,” in order that what’s gotten again by the consumer has trade-offs in high quality, relevance, and extra.
As a result of RAG can dramatically develop the so-called context window, the variety of complete characters or phrases an LLM has to deal with, utilizing RAG could make a mannequin’s context window an even bigger challenge than it will be.
Some LLMs can deal with many extra tokens — on the order of 1,000,000, for Gemini — some far much less. That reality alone might make some LLMs higher at dealing with RAG than others.
Each examples, hyper-parameters and context size affecting outcomes, stem from the broader undeniable fact that, because the Peking students observe, RAG and LLMs every have “distinct targets”. They weren’t constructed collectively, they’re being bolted collectively.
It could be that RAG will evolve extra “superior” strategies to align with LLMs higher, or, it might be the case that LLM design has to begin to incorporate selections that accommodate RAG earlier within the growth of the mannequin.
Attempting to make LLMs smarter about RAG
Students are spending lots of time lately learning intimately failure circumstances of RAG-enabled LLMs, partly to ask a elementary query: what’s missing within the LLM itself that’s tripping issues up?
Scientists at Chinese language messaging agency WeChat described in a analysis paper in February how LLMs do not at all times know how one can deal with the info they retrieve from the database. A mannequin would possibly spit again incomplete info given to it by RAG.
“The important thing motive is that the coaching of LLMs doesn’t clearly make LLMs discover ways to make the most of enter retrieved texts with assorted high quality,” write Shicheng Xu and colleagues.
To cope with that challenge, they suggest a particular coaching methodology for AI fashions they name “an info refinement coaching methodology” named INFO-RAG, which they present can enhance the accuracy of LLMs that use RAG knowledge.
The concept of INFO-RAG is to make use of knowledge retrieved with RAG upfront, because the coaching methodology for the LLM itself. A brand new dataset is culled from Wikipedia entries, damaged aside into sentence items, and the mannequin is skilled to foretell the latter a part of a sentence fetched from RAG by being given the primary half.
Subsequently, INFO-RAG is an instance of coaching a LLM with RAG in thoughts. Extra coaching strategies will most likely incorporate RAG from the outset, seeing that, in lots of contexts, utilizing RAG is what one needs LLMs to do.
Extra delicate elements of the RAG and LLM interplay are beginning to emerge. Researchers at software program maker ServiceNow described in April how they might use RAG to depend on smaller LLMs, which runs counter to the notion that the bigger a big language mannequin, the higher.
“A well-trained retriever can scale back the dimensions of the accompanying LLM at no loss in efficiency, thereby making deployments of LLM-based methods much less resource-intensive,” write Patrice Béchard and Orlando Marquez Ayala.
If RAG considerably permits dimension discount for a lot of use circumstances, it might conceivably tilt the main target of LLM growth away from the size-at-all-cost paradigm of at this time’s more and more massive fashions.
There are alternate options, with points
Essentially the most distinguished various is fine-tuning, the place the AI mannequin is retrained, after its preliminary coaching, through the use of a extra targeted coaching knowledge set. That coaching can impart new capabilities to the AI mannequin. That strategy has the advantage of producing a mannequin that might use particular information encoded in its neural weights with out counting on entry to a database through RAG.
However there are points explicit to fine-tuning as nicely. Google scientists described this month that there are problematic phenomena in fine-tuning, such because the “perplexity curse”, through which the AI mannequin can not recall the mandatory info if it is buried too deeply in a coaching doc.
That challenge is a technical facet of how LLMs are initially skilled and requires particular work to beat. There can be efficiency points with fine-tuned AI fashions that degrade how nicely they carry out relative to a plain vanilla LLM.
High-quality-tuning additionally implies getting access to the language mannequin code to re-train it, which is an issue for individuals who do not have source-code entry, such because the shoppers of OpenAI or one other industrial vendor.
As talked about earlier, operate calling at this time supplies a easy means for GPT or Claude LLMs to reply easy questions. The LLM converts a pure language question similar to “What is the climate in New York Metropolis?” right into a structured format with parameters, together with identify and a “temperature” object.
These parameters are handed to a helper app designated by the programmer, and the helper app responds with the precise info, which the LLM then codecs right into a natural-language reply, similar to: “It is presently 76 levels Fahrenheit in New York Metropolis.”
However that structured question limits what a consumer can do or what an LLM may be made to soak up for instance within the immediate. The true energy of an LLM ought to be to area any question in pure language and use it to extract the proper info from a database.
A less complicated strategy than both fine-tuning or operate calling is called in-context studying, which most LLMs do anyway. In-context studying entails presenting prompts with examples that give the mannequin an indication that enhances what the mannequin can do subsequently.
The in-context studying strategy has been expanded to one thing referred to as in-context information enhancing (IKE), the place prompting through demonstrations seeks to nudge the language mannequin to retain a specific reality, similar to, “Joe Biden”, within the context of a question, similar to, “Who’s the president of the US?”
The IKE strategy, nevertheless, nonetheless could entail some RAG utilization, because it has to attract details from someplace. Counting on the immediate could make IKE considerably fragile, as there is not any assure the brand new details will stay inside the retained info of the LLM.
The highway forward
The obvious miracle of ChatGPT’s arrival in November of 2022 is the start of a protracted engineering course of. A machine that may settle for natural-language requests and reply in pure language nonetheless must be fitted with a solution to have correct and authoritative responses.
Performing such integration raises elementary questions concerning the health of LLMs and the way nicely they cooperate with RAG applications — and vice versa.
The consequence might be an rising sub-field of RAG-aware LLMs, constructed from the bottom as much as incorporate RAG-based information. That shift has massive implications. If RAG information is particular to a area or an organization, then RAG-aware LLMs might be constructed a lot nearer to the top consumer, somewhat than being created as generalist applications inside the biggest AI corporations, similar to OpenAI and Google.
It appears protected to say RAG is right here to remain, and the established order should adapt to accommodate it, maybe in many alternative methods.






{kind=link}